It looks like gmail.com, but this is just gmɑil.com. The internationalized domain name (IDN) convention allows using non ASCII characters for domain names, which is great for arabic and asian countries, but also allows creating fake domain names that look almost like the original.
How this works?
Domain Names normally support only ASCII characters with specific rules (basically a-z, 0-9 and some special characters such as ‘-‘, ‘_’, etc.). A convention firstly released in 2003 and updated in 2010 allowed the use of Non ASCII characters. It was first implemented in Japan with Japanese symbols (for example 日本.com).
It is applied at the application layer (for instance done by your web browser), which will translate the non-ASCII domain name using the following steps described in more details in this document from Mozilla:
- Nameprep step
- convert the string to unicode
- put all characters in lowercase format
- do some extra character cleanup (e.g. forbidden characters)
- Punycode step
- convert the encoding from 8 to 7 bits using only a-z, 0-9 and hyphen
- append xn-- at the beginning of the string
It will transform http://ジェーピーニック.jp into http://xn--hckqz9bzb1cyrb.jp. This is this ASCII version of the domain name that is passed to the DNS server for resolution.
Is it a security issue?
Risk of phishing by spoofing a legitimate domain name has been a concern and the FAQ on Unicode.org gives an interesting view on that and how they evaluated IDNA2003 vs IDNA2008 regarding phishing:
Q: Doesn’t the removal of symbols and punctuation in IDNA2008 help security?
A: Surprisingly, not really. The vast majority of security exploits are of the form “security-wellsfargo.com”, where no special characters are involved.
[…]
Even among the fraction that are confusable characters, IDNA2008 doesn’t do anything about the most frequent sources of character-based spoofing: look-alike characters that are both letters, like “http://paypal.com” with a Cyrillic “a”. If a symbol that can be used to spoof a letter X is removed, but there is another letter that can spoof X is retained, there is no net benefit.
According to data from Google the removal of symbols and punctuation in IDNA2008 reduces opportunities for spoofing by only about 0.000016%, weighted by frequency. In another study at Google of a billion web pages, the top 277 confusable URLs used confusable letters or numbers, not symbols or punctuation. The 278th page had a confusable URL with × (U+00D7 MULTIPLICATION SIGN – by far the most common confusable); but that page could could be even better spoofed with х (U+0445 CYRILLIC SMALL LETTER HA), which normally has precisely the same displayed shape as “x”.
They even created a script to identify all possible options to spoof a legitimate domain name in their Unicode Utilities: Confusables demo. It is an interesting tool for a webmaster to identify potential domain names to register to protect itself against this risk. See the example for the8layers.com:
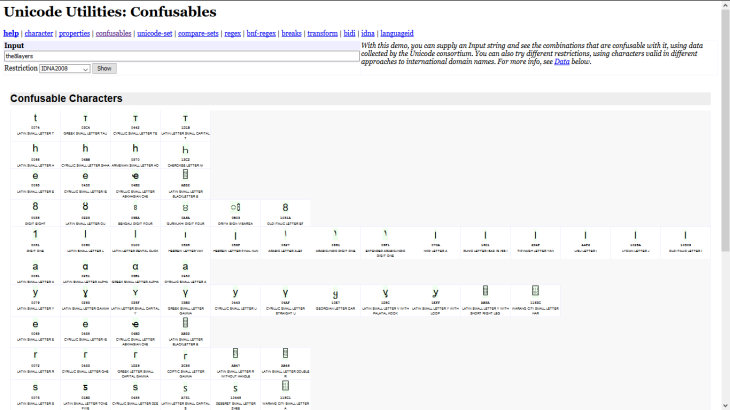
However according to this French specialist, it seems the use of “homographic” domain names which was made simpler thanks to the International Domain Name norm has no relation with the increase of phishing efficiency.
I tend to agree with this especially due to the fact that today all browsers I could test are actually translating the IDNs into their ASCII version immediately after it has been entered, so people would immediately spot the difference:

Do you think this norm is useful? Share your views in the comments!
Sources:
